You can use vals to scrape websites, either by fetching HTML and using a parsing library, or by making an API call to an external service that runs a headless browser for you.
Locate the HTML element that contains the data you need
Section titled “Locate the HTML element that contains the data you need”Right click on the section of a website that contains the data you want to fetch and then inspect the element. In Chrome, the option is called Inspect and it highlights the HTML element in the Chrome DevTools panel.
For example, to scrape the introduction paragraph of the OpenAI page on Wikipedia, inspect the first word of the first paragraph.
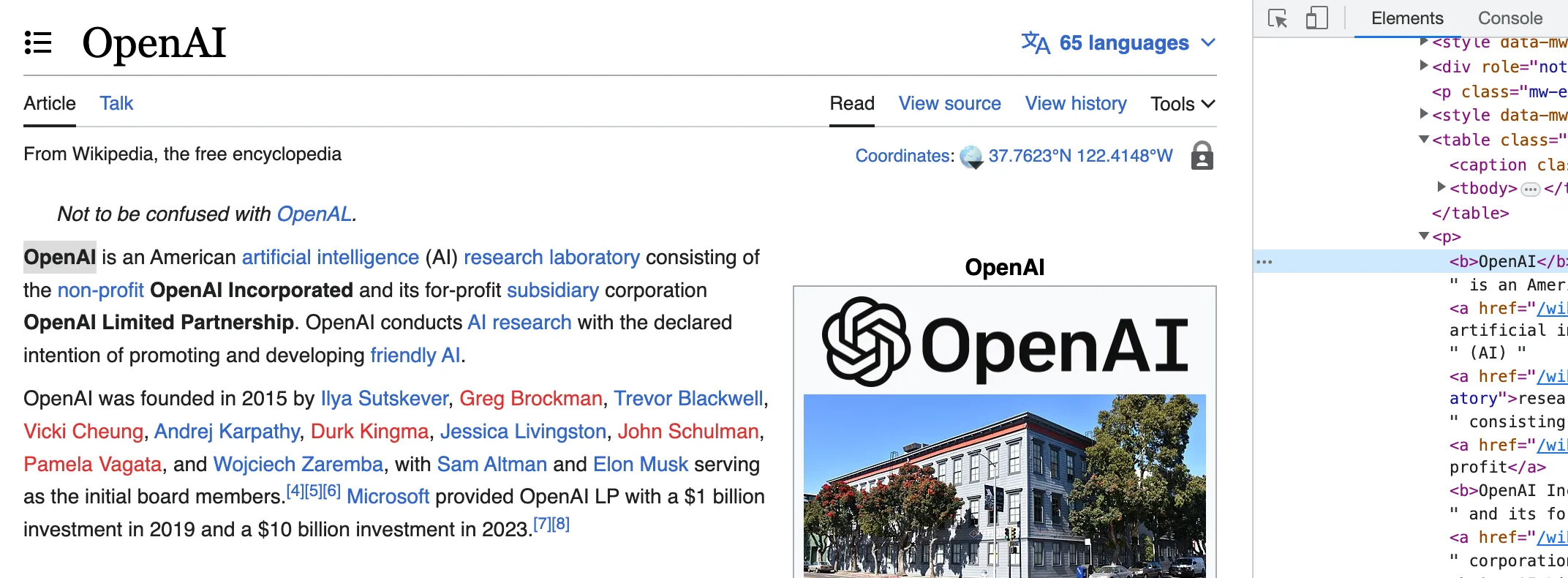
In the Elements tab, look for the the data you need and right click the
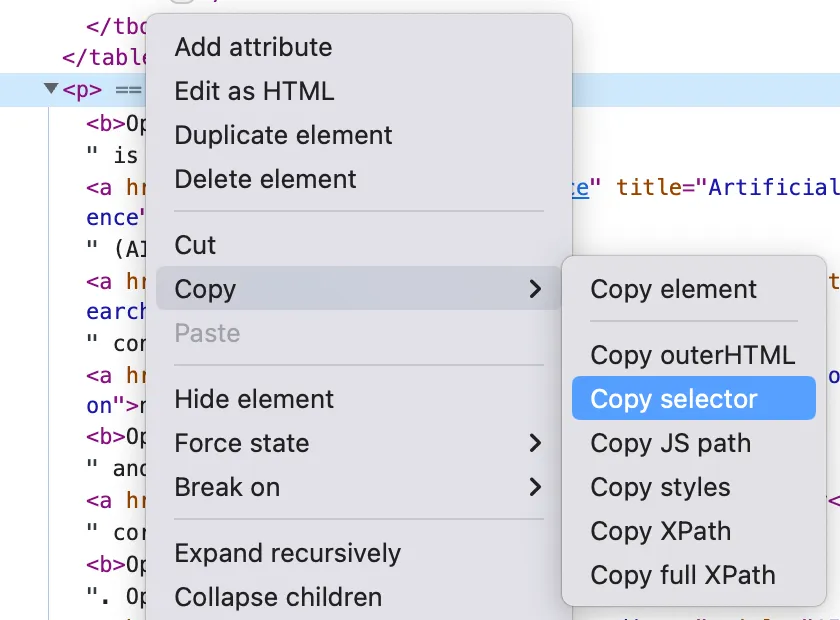
parent element and choose Copy selector to get the
CSS selector:
#mw-content-text > div.mw-parser-output > p:nth-child(7).
If you know a little CSS, it’s better to write your own selector by hand to make
it more generic. This can make the selector less vulnerable to the website being
updated and, e.g., class names changing. In this case, you can use
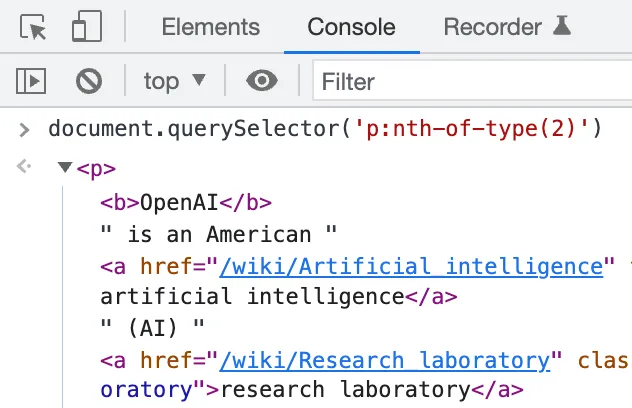
p:nth-of-type(2).
Optionally, use document.querySelector in the Console to check your CSS
selector is correct.
Parsing HTML
Section titled “Parsing HTML”The OpenAI page on Wikipedia is rendered on the server and arrives as a complete HTML document. This makes it a good fit for cheerio which parses HTML markup and provides an API for traversing/manipulating the resulting data structure. We also recommend node-html-parser and linkedom.
import { fetchText } from "https://esm.town/v/stevekrouse/fetchText?v=6";import { load } from "npm:cheerio";
const html = await fetchText("https://en.wikipedia.org/wiki/OpenAI");const $ = load(html);// Cheerio accepts a CSS selector, here we pick the second <p>const intro = $("p:nth-of-type(2)").first().text();console.log(intro);OpenAI is an American artificial intelligence (AI) research organization consisting of the non-profit OpenAI, Inc.[5] registered in Delaware and its for-profit subsidiary OpenAI Global, LLC.[6] One of the leading organizations of the AI Spring,[7][8][9] OpenAI researches artificial intelligence with the declared intention of developing "safe and beneficial" artificial general intelligence, which it defines as "highly autonomous systems that outperform humans at most economically valuable work".[10] OpenAI has developed several large language models, advanced image generation models, and previously, also open-source models.[11][12]API call to external services
Section titled “API call to external services”Check out Browserbase examples: browserbase and browserbaseUtils.